[AI Semiconductor] GPU and TPU
1. Graphic Processing Unit
Background Knowledge
- Kernel: OS의 핵심 역할을 수행하는 소프트웨어. OS와 하드웨어 간의 interface 역할을 하며 시스템의 자원 관리 프로세스 스케줄링, 메모리 관리, 파일 시스템 관리 등의 중요한 기능을 수행한다. 시스템의 가장 하위에 위치하며, OS의 다른 부분과 달리 직접 하드웨어와 상호작용한다.
- Instruction: 컴퓨터에서 수행할 작업을 나타내는 기본적인 명령어
- Program: 컴퓨터를 사용해 어떤 일을 처리하기 위해 순차적으로 구성된 instruction들의 집합
- Process: 메모리에 적재되고 CPU 자원을 할당받아 실행되고 있는 프로그램
- Thread: 프로세스가 할당받은 자원을 이용하는 실행 단위(instruction의 집합)
- Single thread: 하나의 프로세스에서 하나의 작업만 처리할 수 있는 스레드.
- Multi thread: 하나의 프로세스에서 여러 개의 스레드가 동시에 실행되는 것
- SIMD (single instruction multiple data): 하나의 명령어로 여러 개의 data를 동시에 처리하는 컴퓨터 architecture. CPU에서 사용되며 GPU에서는 SIMT가 사용된다.
- SIMT (Single instruction multiple threads): 여러 개의 thread가 하나의 명령어를 동시에 수행
CPU vs. GPU
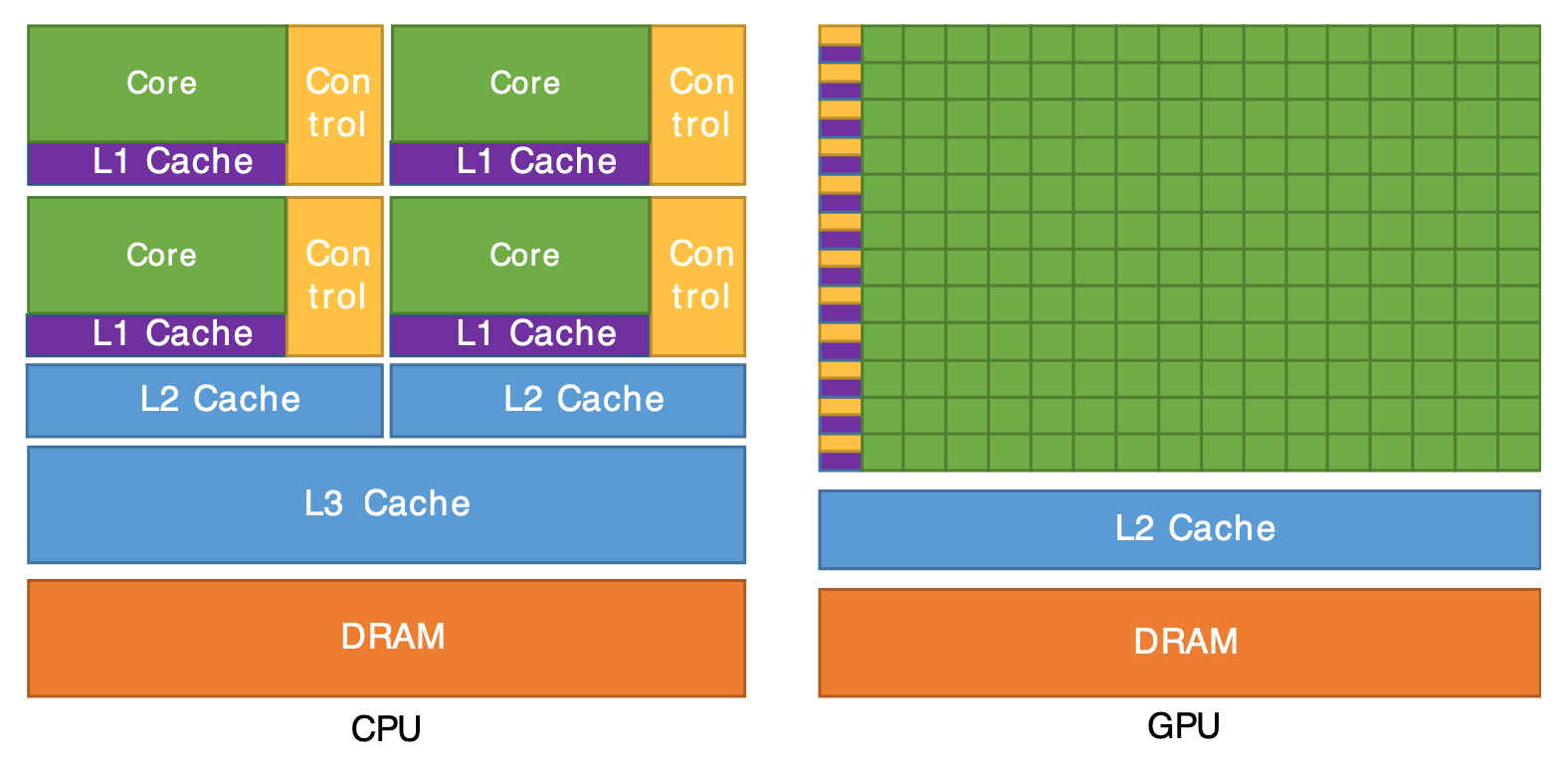
- CPUs can handle more complex workflows compared to GPUs.
- CPUs don’t have as many arithmetic logic units (ALU) or floating point units (FPU) as GPUs.
- CPUs have more cache memory than GPUs.
- GPUs are designed for workloads that can be parallelized to a significant degree
CUDA and GPGPU
Nvida CUDA
- one of the key enabling technologies for GPGPU. First APIs to simpifty the task of programming numerically intensive routines such as matrix manipulation, Fast Fourier Transforms, and decryption algorithms, which enable to be accelerated on GPUs.
- CUDA를 사용하면 CPU와 GPU를 함께 사용하여 성능을 극대화할 수 있다. CPU는 순차적인 작업을 처리하고 GPU는 대량의 데이터를 병렬로 처리하는 등 작업을 분담하여 처리하게 된다.
GPGPU (General-Purpose GPU)
GPU Organization
- CUDA Core: 하나의 thread를 수행한다.
- Load/Store Unit: memory address를 저장하고 있다.
- Special Function Unit (SFU): sine, cosine, reciprocal, square root 등 특수한 함수를 수행한다. deep learning에서는 activation function을 수행할 때 종종 사용된다.
- 64KB Configurable Shared Memory / L1 Cache: 자주 사용하는 걸 저장하기 위해 사용한다.
- Dual Warp Scheduler: SIMT를 구현한다. Instruction을 병렬적으로 뿌려서
2. Tensor Processing Unit
- AI accelerator application-specific integrated circuit (ASIC) for neural network machine learning
- developed by Google, using Google’s won TensorFlow software
TPU Instructions
- Read_Host_Memory: reads data from the CPU host memory into the Unified Buffer (UB)
- Read_Weights read weights from Weight Memory into the Weight FIFO as input to the Matrix Unit
- MatrixMultiply/Convolve causes the Matrix Unit ro perform a matrix multiply or a convolution from the Unified Buffer into the Accumulators
- Activate performs the nonlinear function of the artificial neuron, with options for ReLU, Sigmoid, and so on.
- Write_Host_Memory writes data from the Unified Buffer into the CPU host memory
TPU Microarchitecture
- TPU 마이크로아키텍처의 철학은 행렬 유닛을 계속 바쁘게 유지하는 것이다. 이는 CISC 명령어에 대해 4단계 파이프라인을 사용하며, 각 명령어가 별도의 단계에서 실행되도록 구성되어 있다. (여러 명령어가 동시에 실행될 수 있도록 설계되었다.)
- 계획은 행렬 곱셈(MatrixMultiply) 명령어와 함께 다른 명령어들의 실행을 겹쳐서 수행하여, 이를 통해 다른 명령어들의 실행을 숨기는 것이다. 이 목표에 따라 Read_Weights 명령어는 접근/실행 분리 철학을 따르며, 주소를 전송한 후에도 웨이트가 Weight Memory에서 가져오기 전에 완료될 수 있다. 행렬 유닛은 입력 활성화나 웨이트 데이터가 준비되지 않으면 정지될 수 있다. (명령어 실행과 데이터 접근을 분리하여 전체 실행 속도를 높이는 방식으로 설계되었다.)
Background Knowledge
computer processor architecture에 대한 2가지 설계 철학이 있다.
- CISC (Complex Instruction Set Computing): 명령어 집합이 매우 복잡하고 다양한 아키텍쳐를 가진 프로세서. CISC 프로세서는 하나의 명령어로 많은 작업을 수행할 수 있기 때문에 처리 속도가 빠르고 메모리 사용량이 적은 경우가 많다.
- RISC (Reduced Instruction Set Computing): 명령어 집합이 간단하고 일관성 있으면 몇 가지 기본 명령어를 사용하여 작업을 수행하는 아키텍쳐. RISC 프로세서는 명령어 집합이 단순하기 때문에 하드웨어 설계와 구현이 단순해지고 처리 속도가 빨리질 수 있다. 또한 소프트웨어의 개발과 유지보수도 쉬어진다. 하지만 RISC 프로세서는 많은 명령어가 필요한 복잡한 작업을 수행하는 데는 부적합하다.
Systolic Data Flow of Matrix Multiply Unit
실제로는 256x256 크기의 두 matrix간의 연산을 수행하지만 여기서는 설명을 위해 3x3 크기의 두 matrix 연산을 다룬다.
\[\begin{bmatrix} w_{11} & w_{12} & w_{13} \\ w_{21} & w_{22} & w_{23} \\ w_{31} & w_{32} & w_{33} \\ \end{bmatrix} \times \begin{bmatrix} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \\ a_{31} & a_{32} & a_{33} \\ \end{bmatrix} \\ = \begin{bmatrix} w_{11}a_{11} + w_{12}a_{21} + w_{13}a_{31} & w_{11}a_{12} + w_{12}a_{22} + w_{13}a_{32} & w_{11}a_{13} + w_{12}a_{23} + w_{13}a_{33} \\ w_{21}a_{11} + w_{22}a_{21} + w_{23}a_{31} & w_{21}a_{12} + w_{22}a_{22} + w_{23}a_{32} & w_{21}a_{13} + w_{22}a_{23} + w_{23}a_{33} \\ w_{31}a_{11} + w_{32}a_{21} + w_{33}a_{31} & w_{31}a_{12} + w_{32}a_{22} + w_{33}a_{32} & w_{31}a_{13} + w_{32}a_{23} + w_{33}a_{33} \\ \end{bmatrix}\]Reference
https://cvw.cac.cornell.edu/gpu-architecture/gpu-characteristics/design
https://www.telesens.co/2018/07/30/systolic-architectures/